
[Tensorflow] Chapter 6. 컨볼루션 신경망
본 글은 ‘시작하세요! 텐서플로 2.0 프로그래밍’ 을 바탕으로 작성되었습니다.
Chapter 6. CNN
딥러닝과 컨볼루션 신경망이 대중화되면서 이미지 데이터를 다루기가 수월해졌습니다. 가령 고양이와 개를 구분하는 문제는 사람에게는 쉽지만 컴퓨터로는 처리하기 매우 어려운 일이였습니다. 하지만 컨볼루션 신경망을 활용하여 컴퓨터가 사람보다 더 잘 구분하게 되었습니다. 이미지뿐만 아니라 다양한 분야의 비정형 데이터 처리에서 널리 활용되고 있습니다.
특징 추출
여태까지 다뤘던 데이터에는 특징 feature들이 있었습니다. 이에 비해 이미지 데이터에서는 특징을 우리가 찾아내야 합니다. 과거의 비전 vision 연구에서는 특징을 찾기 위한 다양한 방법이 개발되었습니다. 컨볼루션 연산은 이러한 특징 추출 feature extraction 기법 중 하나입니다. 각 픽셀을 본래 픽셀과 그 주변 픽셀의 조합으로 대체하며, 이때 쓰이는 작은 행렬을 필터 filter 혹은 커널 kernel 이라고 합니다.
컨볼루션 연산은 우리말로 합성곱이라고 합니다. 원본 이미지의 각 픽셀을 포함한 주변 픽셀과 필터의 모든 픽셀은 각각 곱연산을 하고 그 결과를 모두 합해서 새로운 이미지에 넣어주게 됩니다.

Figure 6.1 원본 이미지와 필터 행렬의 합성곱
각 필터의 생김새에 따라 물체의 가장자리를 검출한다던가, 날카로운 이미지 효과를 주는 등으로 작동하게 됩니다. 딥러닝 기반에서의 컨볼루션 연산에서는 필터의 생김새를 수작업으로 설정하는 것이 아니라 네트워크가 특징을 추출하는 필터를 자동으로 생성합니다. 학습을 거듭해 특정 패턴을 잘 추출할 수 있도록 적응하게 됩니다.
주요 레이어 정리

Figure 6.2 컨볼루션 신경망의 구조
컨볼루션 신경망, 즉 CNN은 특징 추출기 feature extractor와 분류기 classifier가 합쳐져 있는 형태입니다. 컨볼루션 레이어와 풀링 레이어가 특징 추출기의 역할을 하며, Dense 레이어가 분류기의 역할을 합니다. 레이어를 하나씩 살펴보겠습니다.
컨볼루션 레이어
컨볼루션 레이어 convolution layer는 말 그대로 컨볼루션 연산을 하는 레이어입니다. 여기서 사용하는 필터는 네트워크의 학습을 통해 자동으로 추출됩니다. 따라서 우리는 필터의 개수만 정해주게 됩니다. 필터의 수가 많으면 다양한 특징을 추출하게 됩니다. 컨볼루션 레이어는 다양한 차원으로 사용할 수 있지만 기본적으로는 2차원을 사용하게 됩니다.
이미지에는 원색으로 구성된 채널 channel이 있습니다. 각 이미지가 가진 색상에 대한 정보를 분리해서 담아놓게 됩니다. 흑백 이미지의 경우 채널이 하나, 컬러 이미지는 보통 RGB의 삼원색으로 된 세 개의 채널을 가지게 됩니다.
컨볼루션 레이어는 각 채널에 대해 계산된 값을 합쳐서 새로운 이미지를 만들어냅니다. 새로운 이미지의 마지막 차원 수는 필터의 수와 동일합니다. 일반적인 컨볼루션 신경망은 여러 개의 컨볼루션 레이어를 쌓으면서 뒤쪽 레이어로 갈수록 필터의 수를 점점 늘리게 되며 따라서 이미지의 마지막 차원 수는 점점 많아집니다.

Figure 6.3 컨볼루션 레이어
컨볼루션 레이어는 다른 레이어와 마찬가지로 tf.keras.layers에서 임포트할 수 있습니다. 코드는 다음과 같습니다.
Conv2D 레이어 생성 코드
주요 인수는 kernel_size, strides, padding, filters 의 네 가지가 있습니다.
-
kernel size
필터 행렬의 크기입니다. 수용 영역 receptive field라고 부릅니다. 앞의 숫자는 높이, 뒤의 숫자는 너비이며 숫자를 하나만 쓸 경우 높이와 너비를 동일한 값으로 사용하게 됩니다.
-
strides
필터가 계산 과정에서 한 스텝마다 이동하는 크기입니다. 기본 값은 (1,1) 이며 (2,2) 로 설정할 경우 한 칸씩 건너뛰면서 계산합니다. kernel_size 와 같이 숫자를 하나만 쓸 경우 높이와 너비를 동일한 값으로 갖게 됩니다. 결과 이미지의 크기에 영향을 주게 됩니다.
-
padding
padding은 입력 이미지 주변에 빈 값을 넣을지를 지정하는 옵션입니다. valid를 줄 경우 빈 값을 사용하지 않으며 same을 줄 경우 출력 이미지의 크기를 입력과 같도록 보존합니다. 빈 값이 0으로 쓰이는 경우 제로 패딩 zero padding 이라고 부릅니다.
-
filters
필터의 개수입니다. 얼마나 많은 특징을 추출할 수 있는지 결정합니다. 너무 많으면 학습 속도가 느리고 과적합이 발생할 수 있습니다.
풀링 레이어
인접한 픽셀들은 비슷한 정보를 갖고 있는 경우가 많기 때문에 이미지의 크기는 줄이면서 중요한 정보만 남기기 위해 서브샘플링 subsampling 이라는 기법을 사용합니다. 연산량과 메모리 사용량은 줄이면서 계산할 정보를 줄여 과적합을 방지하는 효과도 있습니다. 이러한 과정에 사용되는 레이어가 풀링 레이어 pooling layer 입니다. 풀링 레이어에는 Max 풀링 레이어, Average 풀링 레이어 등이 있는데 Max 풀링 레이어가 더 많이 쓰입니다. 코드는 다음과 같습니다.
MaxPool2D 레이어 생성 코드
주요 인수는 pool_size와 strides 입니다.
-
pool_size
한 번에 Max 연산을 수행할 범위입니다. pool_size=(2,2) 인 경우 높이 2, 너비 2의 사각형 안에서 최댓값만 남기는 연산을 수행합니다
-
strides
계산 과정에서 한 스텝마다 이동하는 크기입니다. 컨볼루션 레이어와 같습니다.
풀링 레이어는 가중치가 존재하지 않기 때문에 학습이 되지 않습니다. 네트워크 구조에 따라 생략하기도 합니다.
드롭아웃 레이어
드롭아웃 레이어 Dropout layer 는 네트워크의 과적합을 막기 위한 테크닉입니다. 학습 과정에서 무작위로 일정 비율의 뉴런을 제거하는 방법입니다. 네트워크가 학습할 때 같은 레이어에 있는 뉴런들은 결괏값에 의해 서로 영향을 받게 되어 각 뉴런의 계산 결과를 모두 더해서 나오는 결괏값이 한쪽으로 치우치게 됩니다. 이를 막기 위해 각 학습때마다 드롭아웃 레이어로 확률적으로 일부 뉴런에 대한 연결을 끊고, 테스트할 때는 드롭아웃 레이어를 사용하지 않습니다.
드롭아웃 레이어 생성 코드
인자로는 rate를 받게 되며 제외할 뉴런의 비율을 나타냅니다. 풀링 레이어와 마찬가지로 가중치가 없기 때문에 학습은 되지 않습니다.
정리
컨볼루션 신경망에는 이렇게 세 가지 특징적인 레이어가 사용됩니다. 컨볼루션 레이어는 특징을 추출하는 역할, 풀링 레이어는 중요한 정보만 남기고 계산 부담을 줄이는 역할, 드롭아웃 레이어는 과적합을 방지하는 역할을 합니다. 이 중 학습을 하는 것은 컨볼루션 레이어뿐입니다. 이제 직접 학습시켜보겠습니다.
Fashion MNIST 데이터세트에 적용하기
5장에서 살펴보았던 Fashion MNIST 데이터를 다시 사용하겠습니다. 5장에서는 Dense 레이어를 사용했었는데, 6장에서는 CNN을 사용해서 성능이 얼마나 개선되는지를 살펴보겠습니다.
Fashion MNIST 데이터세트 불러오기 및 정규화
데이터세트를 불러오고 정규화하는 부분은 앞선 5장과 동일합니다. 하지만 이번에는 Conv2D 레이어를 사용할 것입니다. 이미지는 보통 채널을 갖고 있고 Conv2D는 채널을 가진 형태의 데이터를 받도록 설정되어 있기 때문에 이번에는 채널을 갖도록 데이터의 Shape를 바꿔보겠습니다.
데이터세트 reshape
- reshape 이전
(60000, 28, 28) (10000, 28, 28)
- reshpae 이후
(60000, 28, 28, 1) (10000, 28, 28, 1)
데이터는 흑백 이미지이기 때문에 채널을 1개를 갖습니다. 때문에 reshape() 함수를 사용해 데이터의 가장 뒤쪽에 채널 차원을 추가했습니다. 데이터의 수는 달라지지 않습니다.
데이터 확인

[9 0 0 3 0 2 7 2 5 5 0 9 5 5 7 9]
그래프를 그리기 위한 데이터는 2차원이여야 하기 때문에 각 데이터를 대상으로 reshape()를 취해 3차원 데이터를 다시 2차원으로 변환시켰습니다. 라벨이 9는 신발, 0은 티셔츠/상의, 3은 드레스를 의미하므로 잘 분류된 것을 확인할 수 있습니다. 이제 모델을 생성해보겠습니다.
분류를 위한 컨볼루션 신경망 모델 정의
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 26, 26, 16) 160
_________________________________________________________________
conv2d_2 (Conv2D) (None, 24, 24, 32) 4640
_________________________________________________________________
conv2d_3 (Conv2D) (None, 22, 22, 64) 18496
_________________________________________________________________
flatten (Flatten) (None, 30976) 0
_________________________________________________________________
dense (Dense) (None, 128) 3965056
_________________________________________________________________
dense_1 (Dense) (None, 10) 1290
=================================================================
Total params: 3,989,642
Trainable params: 3,989,642
Non-trainable params: 0
_________________________________________________________________
비교를 위해 풀링 레이어 없이 컨볼루션 레이어만 사용한 모델입니다. 총 3개의 Conv2D 모델을 사용했고 그중 첫째 레이어의 input_shape는 (28,28,1) 로 입력 이미지의 높이, 너비, 채널 수를 정의합니다. 필터의 수는 뒤로 갈수록 2배씩 늘어나도록 했습니다. 그 후 Flatten 레이어로 1차원으로 정렬한 후 2개의 Dense 레이어를 사용했습니다. 이제 모델을 정의했으니 학습을 진행해보도록 하겠습니다.
모델 학습
Epoch 1/25
1407/1407 [==============================] - 10s 5ms/step - loss: 0.4646 - accuracy: 0.8344 - val_loss: 0.3912 - val_accuracy: 0.8594
Epoch 2/25
1407/1407 [==============================] - 7s 5ms/step - loss: 0.3373 - accuracy: 0.8770 - val_loss: 0.3671 - val_accuracy: 0.8665
Epoch 3/25
1407/1407 [==============================] - 7s 5ms/step - loss: 0.2826 - accuracy: 0.8954 - val_loss: 0.3990 - val_accuracy: 0.8645
...
Epoch 23/25
1407/1407 [==============================] - 7s 5ms/step - loss: 0.0687 - accuracy: 0.9774 - val_loss: 1.1844 - val_accuracy: 0.8562
Epoch 24/25
1407/1407 [==============================] - 7s 5ms/step - loss: 0.0664 - accuracy: 0.9783 - val_loss: 1.2133 - val_accuracy: 0.8615
Epoch 25/25
1407/1407 [==============================] - 7s 5ms/step - loss: 0.0640 - accuracy: 0.9792 - val_loss: 1.2742 - val_accuracy: 0.8583
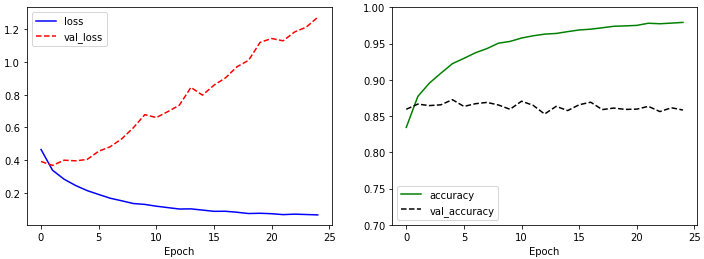
[1.2969107627868652, 0.854200005531311]
왼쪽 그래프를 확인해보면 loss는 감소하고 val_loss는 증가하는 전형적인 과적합의 형태를 나타냅니다. 오른쪽 그래프에서는 훈련 데이터에 대한 모델의 정확도인 accuracy가 빠르게 증가하는 데에 비해 검증 데이터에 대한 정확도 val_accuracy는 학습이 진행될수록 오히려 감소합니다.
마지막 model.evaluate() 함수로 계산되는 결과 중 첫 번째가 테스트 데이터의 loss이고 두 번째가 테스트 데이터의 accuracy 입니다. Dense 레이어에서는 88.3%가 나왔었는데 오히려 못 미치는 성능이 나왔습니다. 이제 풀링 레이어와 드롭아웃 레이어로 개선해보겠습니다.
모델 정의 - 풀링 레이어, 드롭아웃 레이어 추가
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 13, 13, 32) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 11, 11, 64) 18496
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 5, 5, 64) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 3, 3, 128) 73856
_________________________________________________________________
flatten_1 (Flatten) (None, 1152) 0
_________________________________________________________________
dense_2 (Dense) (None, 128) 147584
_________________________________________________________________
dropout (Dropout) (None, 128) 0
_________________________________________________________________
dense_3 (Dense) (None, 10) 1290
=================================================================
Total params: 241,546
Trainable params: 241,546
Non-trainable params: 0
_________________________________________________________________
총 파라미터의 개수가 약 6%로 줄었습니다. 이는 풀링 레이어가 이미지의 크기를 줄여주고 있기 때문에 Flatten 레이어에 들어온 파라미터 수가 많이 줄었기 때문입니다. 또 Dense 레이어 사이에는 드롭아웃 레이어도 추가됐습니다. 풀링 레이어와 드롭아웃 레이어는 과적합을 줄이는 효과를 가지고 있습니다. 이제 다시 학습해보겠습니다.
학습 - 풀링 레이어, 드롭아웃 레이어 추가
Epoch 1/25
1407/1407 [==============================] - 7s 5ms/step - loss: 0.5218 - accuracy: 0.8111 - val_loss: 0.3617 - val_accuracy: 0.8643
Epoch 2/25
1407/1407 [==============================] - 6s 4ms/step - loss: 0.3587 - accuracy: 0.8692 - val_loss: 0.3352 - val_accuracy: 0.8777
Epoch 3/25
1407/1407 [==============================] - 6s 5ms/step - loss: 0.3171 - accuracy: 0.8843 - val_loss: 0.3197 - val_accuracy: 0.8794
...
Epoch 23/25
1407/1407 [==============================] - 7s 5ms/step - loss: 0.1353 - accuracy: 0.9499 - val_loss: 0.4119 - val_accuracy: 0.8954
Epoch 24/25
1407/1407 [==============================] - 6s 5ms/step - loss: 0.1326 - accuracy: 0.9514 - val_loss: 0.5190 - val_accuracy: 0.8957
Epoch 25/25
1407/1407 [==============================] - 7s 5ms/step - loss: 0.1299 - accuracy: 0.9521 - val_loss: 0.4659 - val_accuracy: 0.8930

[0.4937308728694916, 0.8863999843597412]
val_loss가 증가하는 현상은 여전히 보이고 있지만 아까에 비하면 훨씬 약한 수준이며, val_accuracy는 일정 수준에서 머무르고 있습니다. 분류 성적은 0.886로 더 개선되었으며, 이전 결과는 물론 Dense 네트워크에 비해서도 더 좋은 결과를 보여줍니다. 하지만 여기서 더 성능을 높일 수 있습니다.
퍼포먼스 높이기
CNN에서 퍼포먼스를 높이는 여러가지 방법이 있습니다. 그 중 대표적인 두 가지 방법은 ‘더 많은 레이어 쌓기’ 와 이미지 보강 Image Augmentation 입니다.
더 많은 레이어 쌓기
딥러닝의 역사는 더 깊은 신경망을 쌓기 위한 노력이라고 할 수 있습니다. 여러가지 테크닉을 통해 네트워크 구조를 깊게 쌓는 것이 가능해진 후 CNN에서도 더 깊은 구조가 계속해서 나타났습니다.

Figure 6.4 VGGNet의 아키텍쳐
이번에는 위 그림의 아키텍쳐를 가지고 있는 VGGNet의 스타일로 구성한 네트워크를 사용해 데이터를 분류해보았습니다. VGG는 구조가 단순하면서도 성능이 좋기 때문에 지금도 많이 쓰이는 네트워크 구조 중 하나입니다.
VGGNet 스타일의 모델 정의
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_7 (Conv2D) (None, 28, 28, 32) 320
_________________________________________________________________
conv2d_8 (Conv2D) (None, 28, 28, 64) 18496
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 14, 14, 64) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 14, 14, 64) 0
_________________________________________________________________
conv2d_9 (Conv2D) (None, 14, 14, 128) 73856
_________________________________________________________________
conv2d_10 (Conv2D) (None, 12, 12, 256) 295168
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 6, 6, 256) 0
_________________________________________________________________
dropout_2 (Dropout) (None, 6, 6, 256) 0
_________________________________________________________________
flatten_2 (Flatten) (None, 9216) 0
_________________________________________________________________
dense_4 (Dense) (None, 512) 4719104
_________________________________________________________________
dropout_3 (Dropout) (None, 512) 0
_________________________________________________________________
dense_5 (Dense) (None, 256) 131328
_________________________________________________________________
dropout_4 (Dropout) (None, 256) 0
_________________________________________________________________
dense_6 (Dense) (None, 10) 2570
=================================================================
Total params: 5,240,842
Trainable params: 5,240,842
Non-trainable params: 0
_________________________________________________________________
VGG-19는 특징 추출기의 초반에 컨볼루션 레이어를 2개 겹친 뒤 풀링 레이어 1개를 사용하는 패턴을 2차례, 그 후 컨볼루션 레이어를 4개 겹친 뒤 풀링 레이어 1개를 사용하는 패턴을 3차례 반복합니다.
여기서는 대상 이미지가 작고 연산 능력의 한계도 있으므로 컨볼루션 레이어를 2개 겹치고 풀링 레이어를 1개 사용하는 패턴을 2차례 반복했습니다. 또 네트워크 사이사이에 드롭아웃 레이어를 배치하여 과적합을 방지했습니다.
이제 학습해보도록 하겠습니다.
VGG 스타일의 모델 학습
Epoch 1/25
1407/1407 [==============================] - 15s 8ms/step - loss: 0.5918 - accuracy: 0.7821 - val_loss: 0.3326 - val_accuracy: 0.8780
Epoch 2/25
1407/1407 [==============================] - 10s 7ms/step - loss: 0.3705 - accuracy: 0.8687 - val_loss: 0.2859 - val_accuracy: 0.8921
Epoch 3/25
1407/1407 [==============================] - 10s 7ms/step - loss: 0.3290 - accuracy: 0.8812 - val_loss: 0.2556 - val_accuracy: 0.9004
...
Epoch 23/25
1407/1407 [==============================] - 10s 7ms/step - loss: 0.2279 - accuracy: 0.9192 - val_loss: 0.2233 - val_accuracy: 0.9197
Epoch 24/25
1407/1407 [==============================] - 10s 7ms/step - loss: 0.2286 - accuracy: 0.9194 - val_loss: 0.2052 - val_accuracy: 0.9276
Epoch 25/25
1407/1407 [==============================] - 10s 7ms/step - loss: 0.2307 - accuracy: 0.9182 - val_loss: 0.2051 - val_accuracy: 0.9276

[0.21912600100040436, 0.9230999946594238]
앞선 학습과는 다르게 val_loss가 잘 증가하지 않습니다. 더해서 테스트 데이터에 대한 분류 성적도 많이 뛰어난 모습을 보입니다. 모델이 아직 과적합되지 않아 에포크 수를 늘린다면 더 성능이 좋아질 가능성도 있어 보입니다.
이미지 보강
이미지 보강 Image augmentation은 훈련 데이터에 없는 이미지를 새롭게 만들어내서 훈련 데이터를 보강하는 것입니다. 훈련 데이터의 이미지를 원본으로 삼고 일정한 변형을 가하게 됩니다. 가로로 뒤집거나, 회전시키거나, 기울이거나, 확대하거나, 평행이동시키는 등의 다양한 기법을 활용해 훈련 데이터를 더 다양하게 만들어줍니다. tf.keras는 이러한 작업을 도와주는 ImageDataGenerator가 있습니다.
Image Augmentation 데이터 표시

이처럼 한가지 이미지를 여러 형태로 변형시켜 훈련 데이터를 보강하는 것입니다. 주요 인수는 rotation_range, zoom_range, shear_range, horizontal_flip 등의 인자가 있습니다. flow() 함수는 실제로 보강된 이미지를 생성합니다. 이 함수는 Iterator라는 객체를 만드는데 next() 함수를 활용해 이 객체에서 값을 순차적으로 꺼낼 수 있습니다. augment_size를 100으로 설정했기 때문에 100개의 이미지가 만들어집니다. 그럼 이제 이미지를 생성하고 훈련 데이터에 추가해보겠습니다.
이미지 보강
(90000, 28, 28, 1)
훈련 데이터의 50%인 30,000개의 이미지를 추가하기 위해 augment_size = 30000으로 설정했습니다. 이때 변형할 원본 이미지는 np.random.randint()를 활용하여 무작위로 선택했습니다.
randidx는 정수로 구성된 넘파이 array이고 train_X에서 각 array의 원소가 가리키는 이미지를 한번에 선택했습니다. 이렇게 선택한 데이터에 영향을 주지 않게 하기 위해 copy() 함수로 원본 데이터를 참조하지 않도록 했습니다. 그 후 flow() 함수로 이미지를 생성합니다.
마지막으로 np.concentrate() 함수로 훈련 데이터에 보강 이미지를 추가했습니다. 최종 출력에서 train_X.shape의 차원 수를 확인하여 정상적으로 이미지가 추가됐음을 확인할 수 있습니다. 그럼 이제 학습시켜보도록 하겠습니다.
VGGNet 스타일 네트워크 + 이미지 보강학습
Epoch 1/25
2110/2110 [==============================] - 16s 7ms/step - loss: 0.5779 - accuracy: 0.7894 - val_loss: 0.5395 - val_accuracy: 0.7898
Epoch 2/25
2110/2110 [==============================] - 15s 7ms/step - loss: 0.3784 - accuracy: 0.8635 - val_loss: 0.4995 - val_accuracy: 0.8048
Epoch 3/25
2110/2110 [==============================] - 15s 7ms/step - loss: 0.3371 - accuracy: 0.8788 - val_loss: 0.4571 - val_accuracy: 0.8235
...
Epoch 23/25
2110/2110 [==============================] - 15s 7ms/step - loss: 0.2560 - accuracy: 0.9109 - val_loss: 0.3924 - val_accuracy: 0.8588
Epoch 24/25
2110/2110 [==============================] - 15s 7ms/step - loss: 0.2495 - accuracy: 0.9113 - val_loss: 0.3800 - val_accuracy: 0.8624
Epoch 25/25
2110/2110 [==============================] - 15s 7ms/step - loss: 0.2505 - accuracy: 0.9105 - val_loss: 0.3751 - val_accuracy: 0.8626

[0.2069893777370453, 0.9261999726295471]
증강된 데이터가 학습 데이터에 포함된 validation 세트에 대한 성능은 떨어졌지만 테스트 데이터에 대한 분류 성적은 92.3%에서 92.6%로 약간 더 증가했습니다. val_accuracy 역시 계속해서 증가하고 있는 것으로 보여 더 학습시키면 성적이 더 잘 나올 것이라고 기대할 수 있습니다.
댓글남기기